
競馬で長年馬券を購入しているものの、なかなか収支が安定せずに悩んでいる方は少なくありません。
特に自分の勘や新聞の印だけで予想をしていると、感情に左右されてしまい、冷静な判断を欠くことがあります。
そんな投資競馬において、客観的な判断基準として非常に有効な競馬指標の1つが、JRA-VANが提供する「データマイニング」です。
データマイニングという言葉を聞くと難しく感じるかもしれません。
しかし、データマイニングを活用することで客観的な競馬予想ができるようになり、感情や感覚に依存した分析から脱却して安定した成績を残すきっかけをつかめます。
本記事では、データマイニングの基礎知識から、軸馬・穴馬を見極めるための実践的な活用術、さらには数値の落とし穴までを詳しく解説します。
データに基づいた論理的なアプローチを身につけ、負けない競馬予想の第一歩を踏み出しましょう。
JRA-VANのデータマイニングとは?
データマイニングとは、コンピューターが膨大なデータの中から、人間では気づきにくい特定のパターンや傾向、規則性を見つけ出す分析手法を指します。
そもそもデータマイニングは、マーケティングや気象予報、金融取引など、高度な予測が求められるさまざまな分野で活用されている信頼性の高い統計学です。
決して競馬だけの指標ではないため、データマイニングを活用する際の基礎知識として知っておきましょう。
競馬指標としてのデータマイニングとして有名なのが、JRAの公式関連組織が提供する競馬支援ツール「JRA-VAN」に搭載されている機能です。
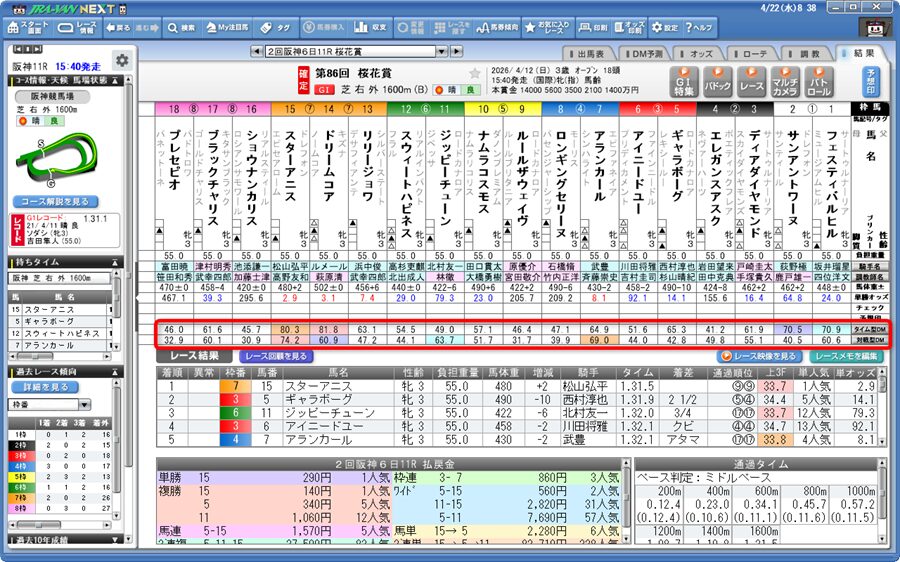
JRA-VANのデータマイニングは、過去数十年にわたる膨大なレース結果をAIに近いアルゴリズムで解析し、出走各馬がそのレースで発揮できる能力を客観的に数値化しています。
主観を排除した数字による評価を確認できるため、多くの競馬ファンが重要な判断材料として利用しています。

データを重視している人にはお勧めの競馬指標です
データマイニングでまとめられている要素
JRA-VANのデータマイニングでは、主に以下の要素を独自の手法で分析・計算し、各馬の期待値を指数として算出しています。
具体的にデータマイニングの算出で参考にしている情報として以下が挙げられます。
- 過去のレース成績: 過去の着順や走破タイム、上がり3ハロンの時計など
- 出走レースの情報: 距離、コース形態(右・左回り)、芝・ダート、馬場状態の適正
- その他の補正要素: 騎手の過去実績、出走馬の脚質バランスから予測されるコース展開
要するに「馬の実力」を数値化したものがデータマイニングです。
データマイニングには、個人の能力では処理しきれない多角的な情報を集約しています。
そのため、競馬新聞の印だけでは見えてこない「馬の真の実力」が浮き彫りになり、客観的な視点から各馬の能力を比較検討できます。
具体的な計算式やアルゴリズムの詳細は非公開となっているため、独自での算出はできません
競馬のデータマイニングは「2種類」ある
JRA-VANのデータマイニングを使いこなす上で、まず理解しておくべきは「スピード型」と「対戦型」という2つの異なる指標です。
どちらのデータマイニングには変わりありませんが、算出方法が違うため数値が持つ意味も変わってきます。
具体的には、スピード型は主にタイムを重視し、対戦型はレースの内容や対戦相手の質を重視します。
2つのデータマイニングを使い分けることで、単一の指数では見逃してしまうような「隠れた実力馬」を発見できる確率が飛躍的に高まります。
投資としての競馬を成立させるためには、それぞれの特徴を正しく把握し、役割を分担させましょう。
スピード型と対戦型の具体的な違いを以下で詳しく解説します。
スピード型データマイニングの特徴
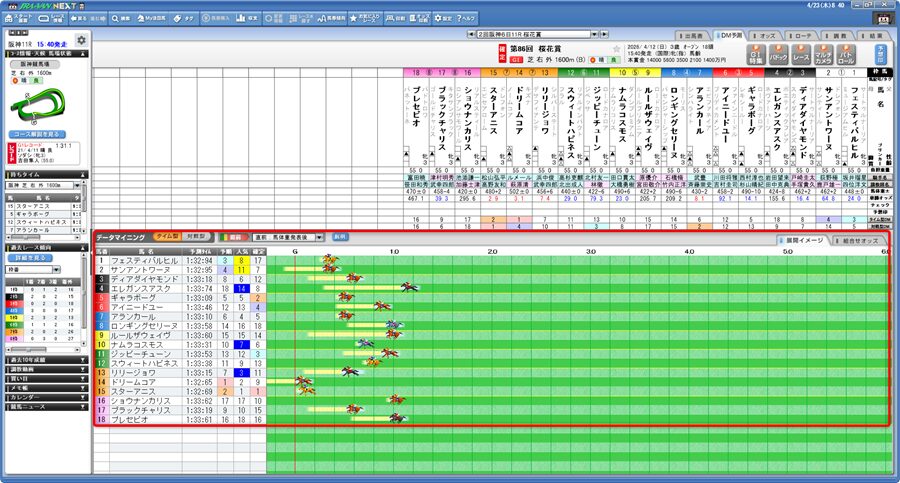
スピード型データマイニングは、過去の走破タイムやスピード能力をベースにした評価指標です。
その名の通り「馬がどれだけ速く走れるか」という純粋なスピード能力を数値化しています。
具体的には、良馬場や重馬場といった馬場状態や、コースごとの起伏などを加味してタイムを補正し、その馬の持ち時計の価値を算出します。
時計勝負になりやすいレースや、先行して逃げ粘るタイプが得意な展開では、このスピード型指標が非常に強力な武器となります。
誰の目にも明らかな「速さ」を可視化しているため、実力が反映されやすい指標です。
素直な馬の実力比較に用いられるのがスピード型です
対戦型データマイニングの特徴
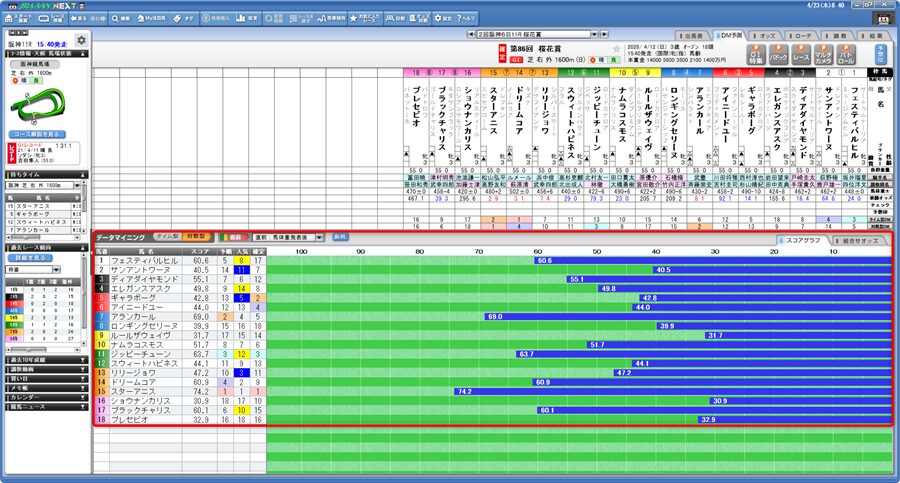
対戦型データマイニングは、過去に戦ってきた相手関係を評価した指標です。
単なるタイムの速さではなく「どのレベルの相手と戦い、どのような結果を残してきたか」という勝負強さや格付けを重視します。
例えば、タイム自体は目立たなくても非常にレベルの高い重賞レースで強敵相手に僅差の勝負を続けてきた馬などは、この対戦型指標で高く評価される傾向にあります。
逆に、弱い相手に対して好タイムで勝ってきた馬は対戦型では評価が下がることもあります。
対戦型データマイニングは、数字上のタイムだけでは判断できない「格の差」やクラスが上がっても通用する底力を見抜く材料になります。
タイムや体重など目に見えない実力を把握する時に用いるのが対戦型です
JRA-VANデータマイニングの見方
JRA-VANのデータマイニングには複数の見方が存在しますが、競馬予想の実践において注目すべきポイントは非常にシンプルです。
基本的には「数値」と「順位」の2点を確認すれば問題ありません。
数値と順位のデータはそれぞれ単独で見るのではなく、当日のオッズ(人気)と照らし合わせることで、その馬の過大(過少)評価の度合いが判断できるようになります。
データの意味を正しく理解し、客観的な実力を把握するスキルを身につけましょう。
データマイニングを「数値」で見る場合
データマイニングを数値で確認する場合、その数字が大きければ大きいほど、相対的に実力が上であると判断されます。
データマイニングの数値には基準があり、一般的には「50」が平均値として設定されています。
数値が「60」を超えてくると、そのレースにおいてはかなり能力が抜けている、あるいは勝利に近い存在であるという高い評価を意味します。
逆に40代前半などの低い数値であれば、客観的なデータからは苦戦が強いられる可能性が高いと予測できます。
数値同士の差がわずかであれば混戦、大きな開きがあれば実力差がはっきりしているレースという風に、レースの全体像を把握するのにも役立ちます。
他の馬の数値の比較して乖離の度合いを調べる時に使います
データマイニングを「順位」で見る場合
データマイニングの数値を確認するのと同時にチェックしたいのが、数値を高い順に並べ替えた「順位」です。
JRA-VANの画面上では、スピード型と対戦型のそれぞれについて、1位から順にランク付けがなされています。
データマイニング順位が高い=算出アルゴリズムにおいて勝つ確率が高いと判断されたことを示します。
特に「スピード順位1位」かつ「対戦順位1位」のように、両方の指標でトップに立っている馬は、データ上では死角が少ない鉄板級の馬と考えられます。
順位で見ることで、出走各馬の相対的な立ち位置を瞬時に理解できるのがメリットです。
人気順位との相関性を調べるのも順位の方がかんたんです
「人気」「数値」「順位」で総合的に判断
データマイニングを用いて競馬予想をする場合、データマイニングの数値や順位を鵜呑みにするのではなく、総合的に判断して選ぶ必要があります。
例えば人気順位よりもマイニング順位が著しく高い馬は「お買い得な馬(期待値が高い馬)」であり、逆に人気が1番なのにマイニング順位が低い馬は「危険な人気馬」であると考えられます。
データマイニングはあくまでも競馬を予想する参考材料であり答えではありません。
1つの指標に依存しすぎるのではなく、これらの要素を天秤にかけることで、的中率を維持しながら回収率を高める投資競馬のスタイルを構築していきましょう。
データマイニングに振り回されないことが上手に活用するコツです
競馬投資におけるデータマイニングの基本的な活用法
データマイニングを単なる予想ツールとしてではなく、資産を増やすための「投資判断材料」として使うためには、戦略的な活用が必要です。
特に的中率を重視して土台を作る「軸馬選び」と回収率を跳ね上げる「穴馬選び」では、注目すべきマイニングの種類が異なります。
まずは、データが教えてくれる情報の特性を理解し、自分の馬券スタイルに合わせて使い分ける基礎を固めましょう。
軸馬を探したい時は「スピード型」
連対式馬券で軸馬を探すうえでデータマイニングを使うなら、スピード型がおすすめです。
スピード型は馬の純粋な身体能力を反映しやすいため、実際のレース結果や人気順位とも連動しやすいからです。
具体的にはスピード型の指数が高く、なおかつ人気上位の馬を軸馬候補として考えます。
反対に、スピード型の指数が高くても上位人気に入っていない馬や、他の上位人気の馬に比べてスピード型の指数が低い馬は軸馬候補から外して戦略を立ててください。
また、軸馬以外にも単勝や複勝で一点狙いする人も、データマイニングはスピード型の指数は参考になります。
手堅い馬券で攻める時はスピード型の指数を軸に考えていくのがおすすめです
穴馬を見つけたい時は「対戦型」
高配当を狙うための穴馬探しをするのにデータマイニングを使うなら、対戦型データマイニングが威力を発揮します。
対戦型はタイムに表れない底力を評価するため、スピード型指数や当日の人気と乖離(かいり)が起きやすい傾向にあります。
例えば、中位人気や下位人気であっても対戦型マイニングが安定して上位にいる馬は、上位人気の馬を押しのけて馬券に絡む実力を持っているとも見れます。
反対に、上位人気なのに対戦型マイニングが低い馬は、馬券に絡まずに終わる可能性を秘めていると考えられます。
ヒモ馬を対戦型マイニングを使って探すことで、ある程度配当が高く的中する可能性を秘めた馬券で勝負することができます。
レースの荒れ具合を調べるのにも対戦型はおすすめです
買う馬券によっては両方活用
競馬のデータマイニングには、スピード型と対戦型の2つの指標がありますが「どちらか一方しか使ってはいけない」というルールはありません。
むしろ、スピード型と対戦型の両方を活用することで、より精度の高い競馬予想ができます。
例えば、軸馬を選ぶ時にスピード型と人気順位で候補を絞りつつ、対戦型をチェックすることで、軸馬としての信ぴょう性を裏付けることができます。
また、スピード型と対戦型を比較しながら馬を厳選することで、馬券を買う馬の数が厳選できるため、買い目を減らすことにもつながります。
特にある程度配当の高い馬券で勝負する際は、買い目の多さがリスクになりますが、2つのデータマイニングを使うことで、トリガミリスクの管理が可能です。
戦略的に両方の指標を使いこなすことが、競馬投資における最終的な的中率・回収率のアップに直結するので、2つの指標を効率よく使いましょう。
大阪競馬式データマイニングの使い方
データマイニングは、様々な競馬手法やロジックに採用されている指標です。
大阪競馬でも、分析にデータマイニングを採用しており、他の指標やデータと併用することで、勝率や回収率などといった成績向上に大きく貢献します。
具体的に大阪競馬ではデータマイニングを以下のように使います。
レース展開を予測・分析
大阪競馬では、開催されるレースの展開を予測するのにデータマイニングを用います。
具体的には、人気順位・スピード型の順位・対戦型の順位の3つの相関性からレースの荒れ具合を予測します。
3つの順位の相関性が高いレースは、上位人気が馬券を独占する可能性が高く、反対に相関性が低いレースは荒れる可能性があると考えます。
レースの展開が予測できれば、自分が狙っているオッズゾーンの馬券が的中しやすいレースに狙いを絞れるため、的中率がアップすると同時にムダなはずれ馬券を買わずに済みます。
特に競馬投資をするにあたって、レースの厳選は非常に重要です。
レースを厳選する重要性について以下のページで紹介しているので、データマイニングを活用して勝負するレースを見極める力をつけましょう。
馬券の購入金額を減らすのにデータマイニングは有効です

馬券候補になる馬を厳選
大阪競馬では、レース展開だけでなく馬券候補を探す際にもデータマイニングを活用します。
大阪競馬では基本的に「複勝一点買い」が主流のため、上位人気かつデータマイニングの数値が高い馬を中心に馬券候補を選びます。
具体的には「人気が高くスピード型と対戦型のどちらの指数も高い馬」を選出し、オッズが一定以上あれば勝負します。
もちろん人気順位とデータマイニングのみで判断するのではなく、馬柱をはじめとした別の競馬指標で根拠での裏付けは欠かせません。
複数頭いる馬券候補の馬をさらに絞り込むための手段としてデータマイニングを用います。
馬柱の活用法については以下のページで紹介しているので、データマイニングと併用して分析力を高めてください。
データマイニングだけに依存すると予想がブレるので他の指標との併用がおすすめです

穴馬を探す時の参考材料
大阪競馬では、手堅い馬券だけでなく穴馬を狙う際にもデータマイニングを活用します。
具体的には中位人気以下の馬でデータマイニングの数値が一定以上の馬が存在する場合、高配当を狙うチャンスとして勝負します。
競馬の人気は、単純に実力だけでなく主観的な分析(調教師のコメントや評論家の意見など)も加味されたうえでの結果です。
つまり馬券になる実力はあるものの、どういうわけか人気が低い馬が出てしまう可能性があるのです。
データマイニングは、実力に伴った評価をされていない馬を探す材料として利用できます。
データマイニングを使って穴馬を狙う時のポイントについては、以下のページで紹介しているので、ぜひ参考にしてください。
勝負できる機会は少ない点に注意してください
データマイニングで競馬予想する時の注意点
最後にデータマイニングを用いた競馬予想をする上での注意点を紹介します。
データマイニングは非常に便利なツールですが、決して万能な「魔法の杖」ではありません。
数字の性質を正しく理解せずに盲信してしまうと、思わぬ損失を招く恐れがあります。
競馬は生き物が行う競技であり、当日の天候や急な馬体重の増減、馬の気配など、デジタルな数値だけでは測りきれない不確定要素が常に存在します。
データマイニングを最大限に活かすために、利用にあたっての注意点もしっかりと把握しておきましょう。
「数値が高い=必ず勝つ」ではない
データマイニングは、馬の実力を数値化した競馬指標ですが、必ずしも数値が正しいとは限りません。
競馬に限らず他の競技でも、必ずしも実力通りの結果になるとは限らないのと同じように、競馬デモジャイアントキリングが発生する可能性は十分あります。
馬場状態やレース展開によって実力を発揮できないこともありますし、スタートで出遅れることだって考えられます。
データマイニングはあくまで過去の傾向から導き出された「期待値」でしかありません。
データマイニングを鵜呑みにするのではなく、自身の判断を裏付ける根拠の1つとして活用するよう心がけましょう。
どんなに頑張って予想を立てても外れる時は外れます
定期的に数値が更新される
JRA-VANのデータマイニングを利用する際は、変動することも念頭に入れて分析・予想に使う必要があります。
JRA-VANのデータマイニングは、開催前日の夜から数値が表示され、定期的に変更されます。
最終的な数値が確定するのは、出走の約1時間前となるため、前日の夜と出走前とでデータマイニングの数値が変わっていることは珍しくありません。
特に馬場状態の変化や出走取り消しなどがあった場合は大きく変動します。
データマイニングを用いて競馬予想をするなら、少なくとも当日の朝は必ずチェックしましょう。
数値が大きく変わるレースは信ぴょう性が低いので勝負しないほうが良いでしょう
JRA-VANへ加入しないといけない
データマイニングは、JRA-VANが独自に開発・提供している有料サービスの一部です。
そのため、残念ながら完全無料で利用することはできません。
データマイニングの数値をチェックしたいのであれば、PC版の「JRA-VAN NEXT」やスマホアプリ版への加入が必要です。
最も手軽なプランであれば月額880円程度から利用可能ですが、これを「高い」と感じるか「必要経費」と捉えるかは人それぞれ。
競馬をギャンブルではなく投資として捉えるのであれば、精度の高い情報を得るためのコストとして割り切り、活用していく姿勢が求められます。
経費をかけられないのなら競馬を投資として取り組むのはおすすめしません
まとめ
- データマイニングは特定のパターンや傾向、規則性を見つけ出す分析手法のこと
- 競馬のデータマイニング指標はJRA-VANから確認できる
- 競馬のデータマイニングには「スピード型」と「対戦型」の2種類がある
- 2つのデータマイニングを用いることで競馬予想の精度を上げられる
- レース展開や軸馬・ヒモ馬を選ぶ基準としてデータマイニングが使える
本記事では、競馬におけるデータマイニングの使い方について紹介しました。
データマイニングは、メジャーな競馬指標の1つであり、多くの人が利用しています。
他の競馬指標と違って「スピード型」と「対戦型」の2種類があり、2つの活用法や組み合わせによって、より精度の高い競馬分析ができます。
競馬のデータマイニングは有料ではあるものの、JRA-VANから閲覧できるため、がっつり競馬予想を楽しんでいる人はもちろん、競馬を投資として挑んでいる人にもおすすめの競馬指標です。
データを用いて競馬予想をしたいのなら、ぜひデータマイニングを使ってみてください。







